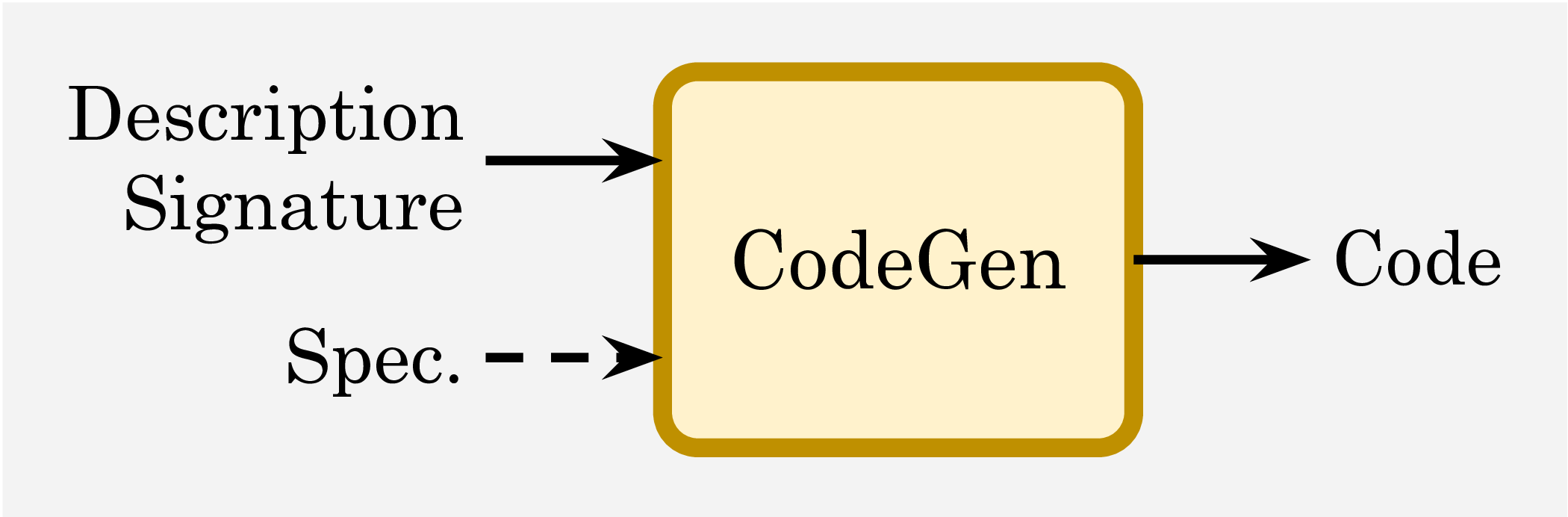
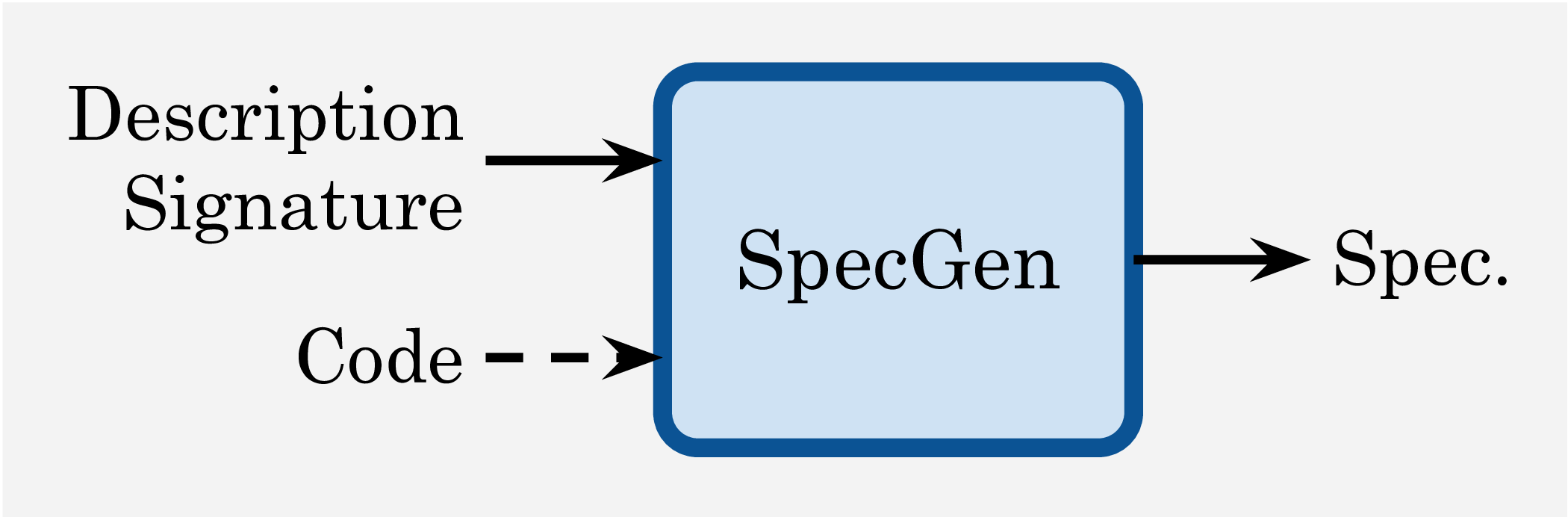
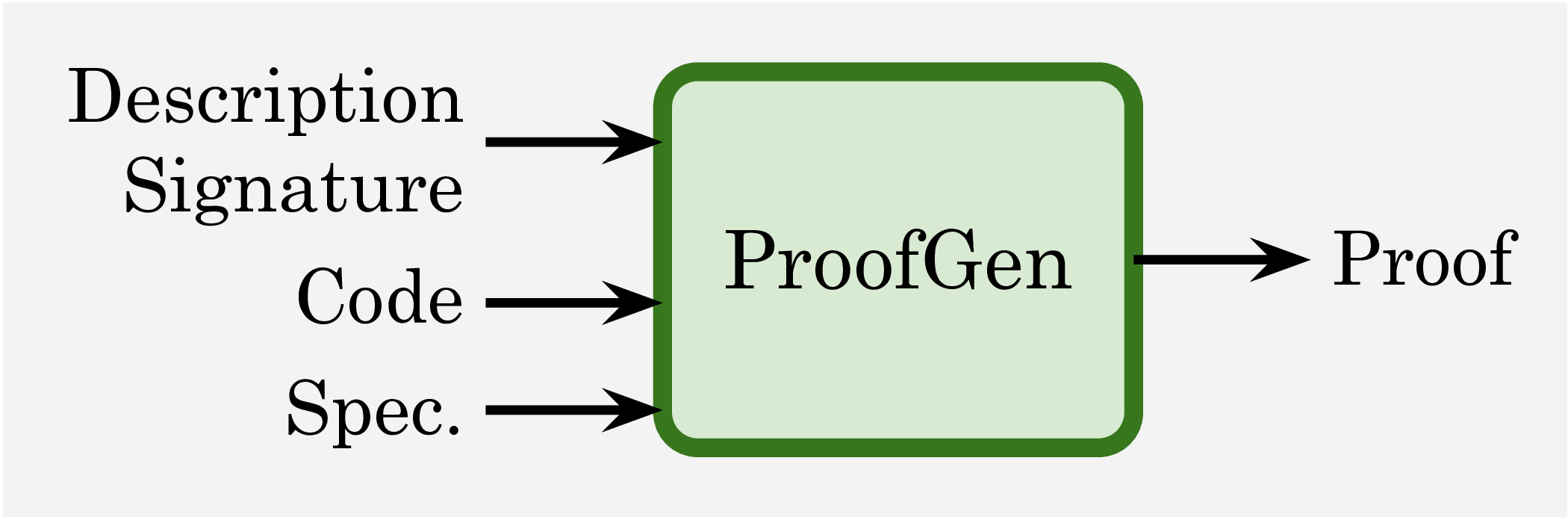
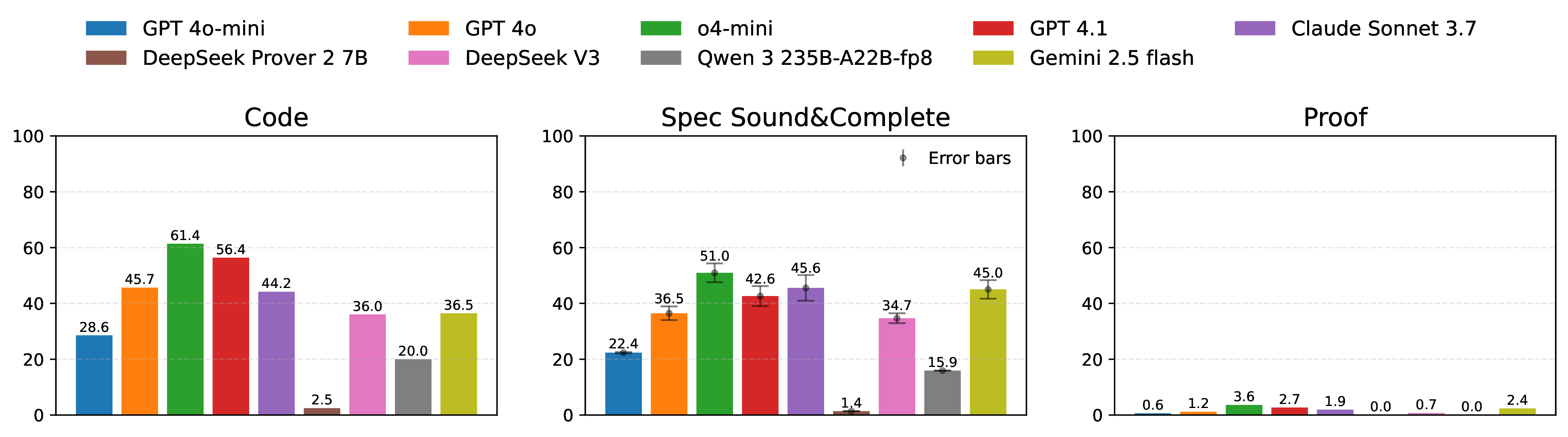
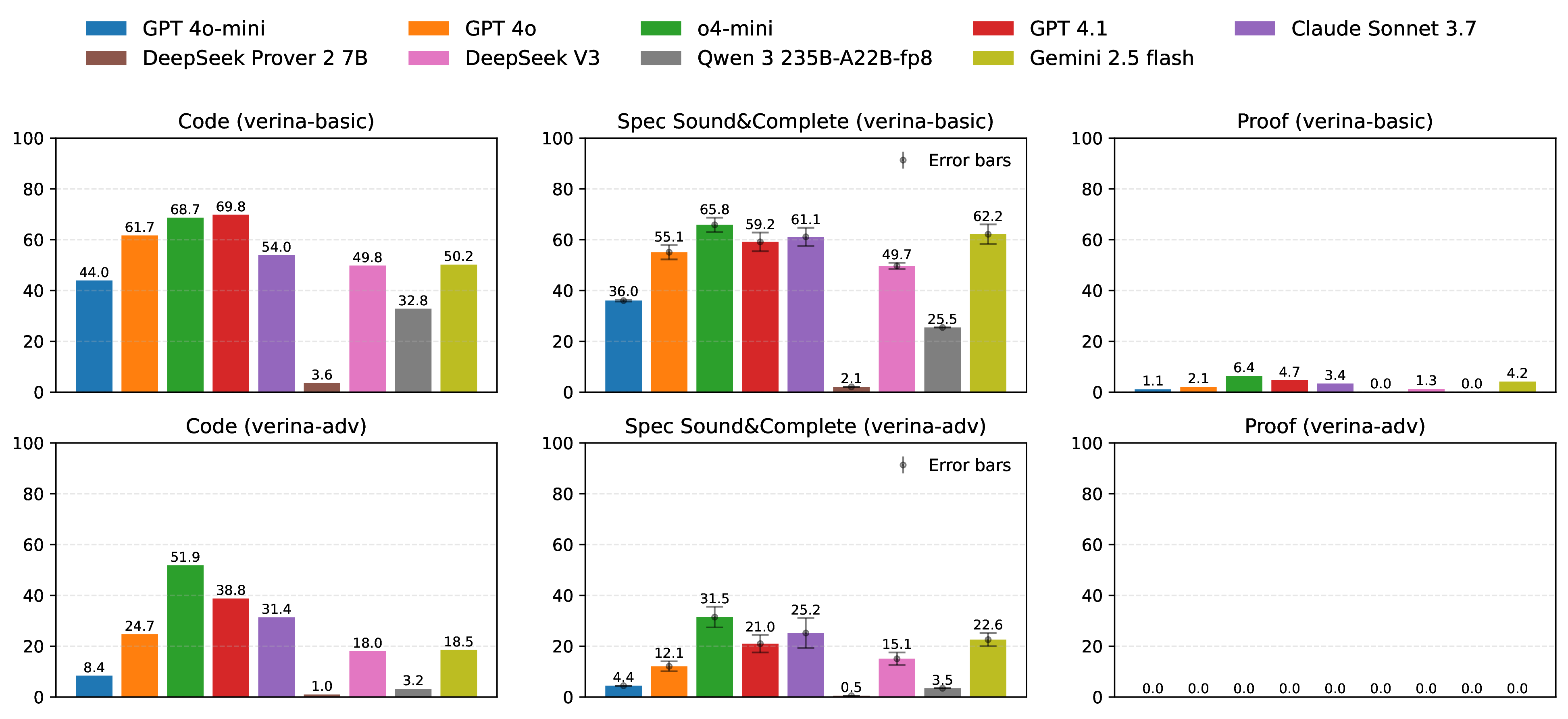
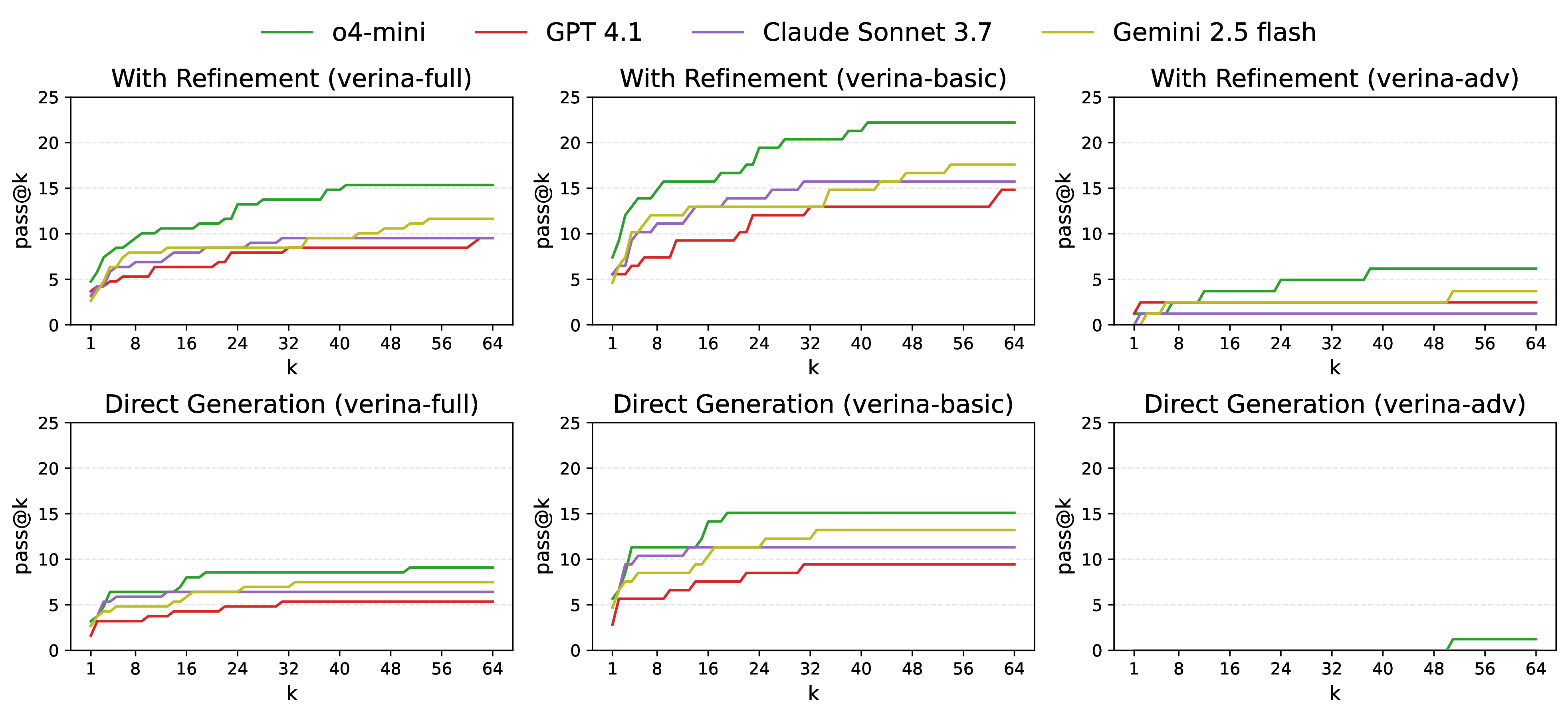
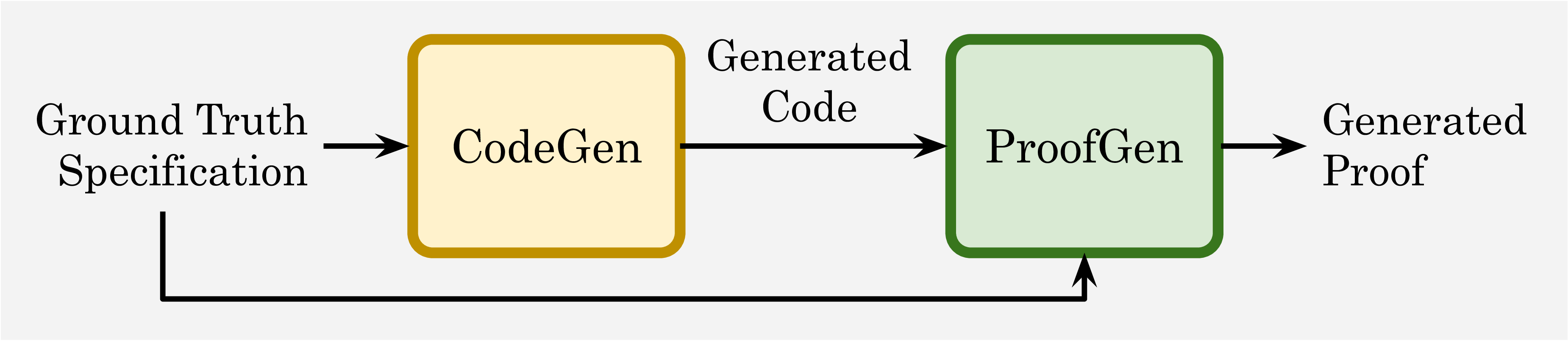
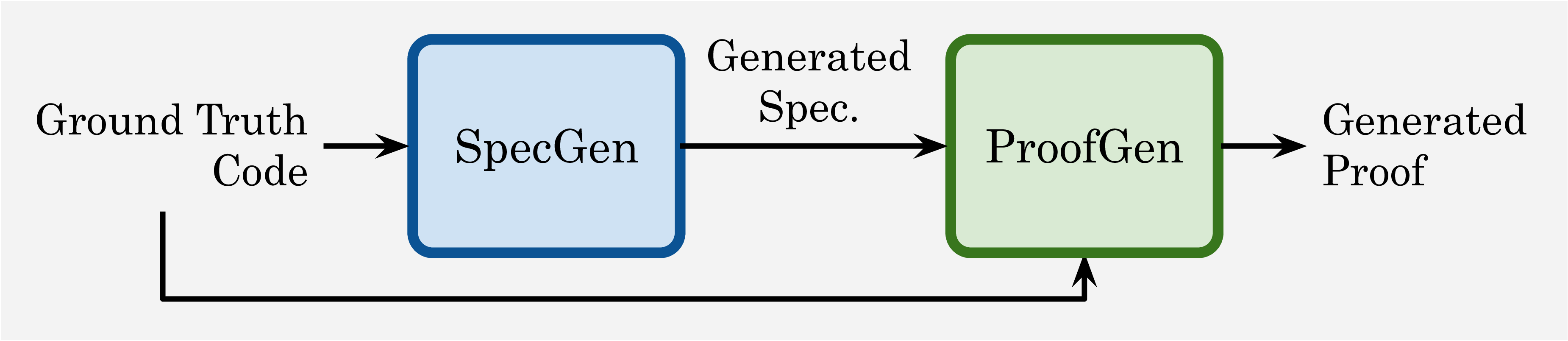
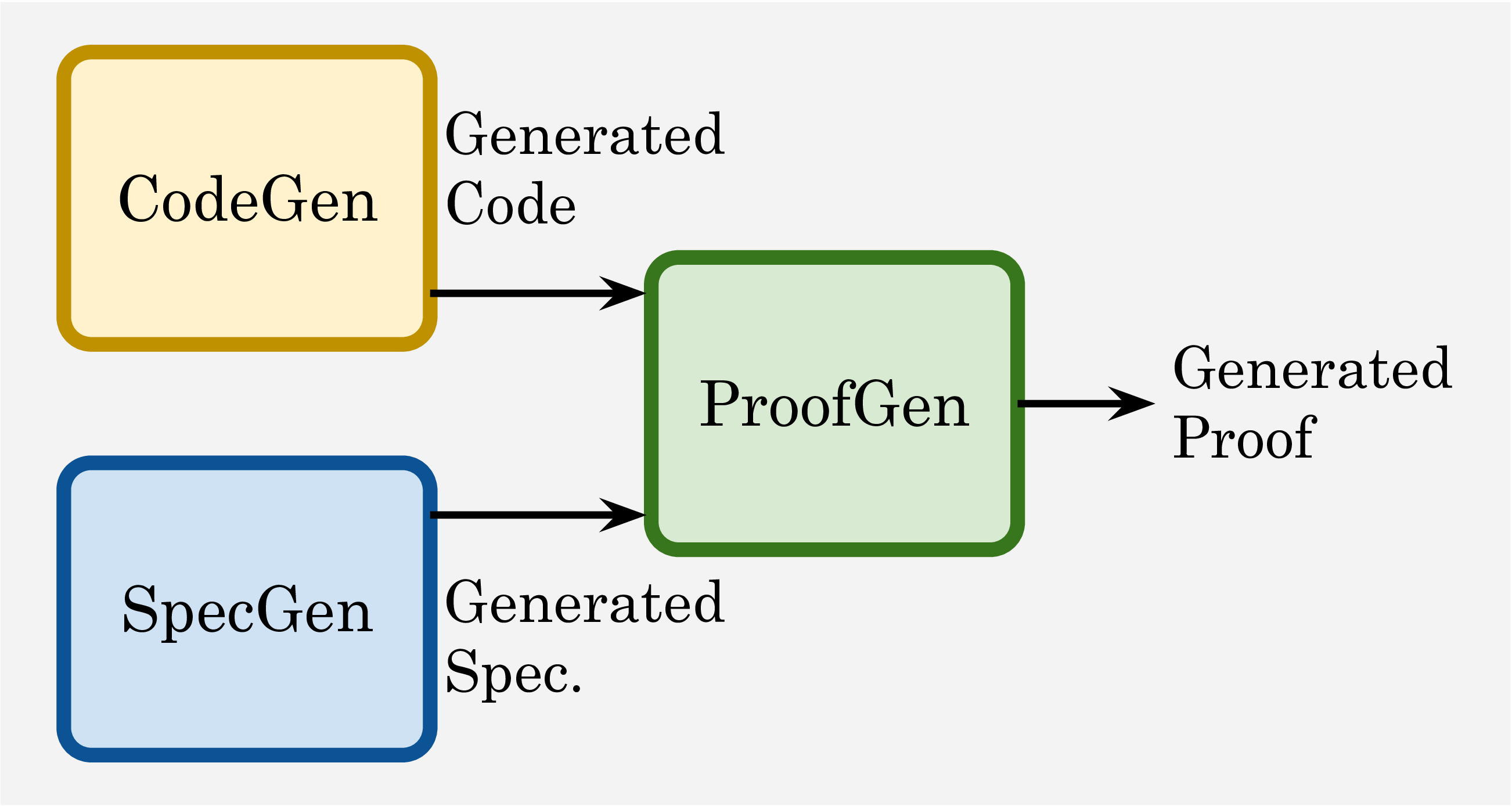
Each instance in VERINA consists of a comprehensive set of
components designed to support rigorous evaluation of verifiable
code generation:
-- Natural language description of the coding problem
-- Remove an element from a given array of integers at a specified index...
-- Code implementation
def removeElement (s : Array Int) (k : Nat) (h_precond : removeElement_pre s k) : Array Int :=
s.eraseIdx! k
-- Pre-condition
def removeElement_pre (s : Array Int) (k : Nat) : Prop :=
k < s.size -- the index must be smaller than the array size
-- Post-condition
def removeElement_post (s : Array Int) (k : Nat) (result: Array Int)
(h_precond : removeElement_pre s k) : Prop :=
result.size = s.size - 1 ∧ -- Only one element is removed
(∀ i, i < k → result[i]! = s[i]!) ∧ -- Elements before index k remain unchanged
(∀ i, i < result.size → i ≥ k → result[i]! = s[i + 1]!) -- Elements after are shifted
-- Formal proof (establishing code-specification alignment)
theorem removeElement_spec (s: Array Int) (k: Nat) (h_precond : removeElement_pre s k) :
removeElement_post s k (removeElement s k h_precond) h_precond := by
unfold removeElement removeElement_postcond
unfold removeElement_precond at h_precond
simp_all
unfold Array.eraseIdx!
simp [h_precond]
constructor
· intro i hi
have hi' : i < s.size - 1 := by
have hk := Nat.le_sub_one_of_lt h_precond
exact Nat.lt_of_lt_of_le hi hk
rw [Array.getElem!_eq_getD, Array.getElem!_eq_getD]
unfold Array.getD
simp [hi', Nat.lt_trans hi h_precond, Array.getElem_eraseIdx, hi]
· intro i hi hi'
rw [Array.getElem!_eq_getD, Array.getElem!_eq_getD]
unfold Array.getD
have hi'' : i + 1 < s.size := by exact Nat.add_lt_of_lt_sub hi
simp [hi, hi'']
have : ¬ i < k := by simp [hi']
simp [Array.getElem_eraseIdx, this]
-- Comprehensive test cases (both positive and negative)
(s : #[1, 2, 3, 4, 5]) (k : 2) (result : #[1, 2, 4, 5]) -- Positive test with valid inputs and output
(s : #[1, 2, 3, 4, 5]) (k : 5) -- Negative test: inputs violate the pre-condition at Line 12
(s : #[1, 2, 3, 4, 5]) (k : 2) (result : #[1, 2, 4]) -- Negative test: output violates the first clause of the post-condition
(s : #[1, 2, 3, 4, 5]) (k : 2) (result : #[2, 2, 4, 5]) -- Negative test: output violates the second clause of the post-condition at Line 17
(s : #[1, 2, 3, 4, 5]) (k : 2) (result : #[1, 2, 4, 4]) -- Negative test: output violates the third clause of the post-condition at Line 18